

In this C# Tutorial, we’ll do C# Web scraping with HTML Agility Pac, and will learn how to Scrape Google SERPs (Search Results).
So essentially what we’ll do is.
1. Search a query within the Code using HTML Agility Pack in C#
For example, if we search a QUERY in Google, like “Python Projects.” Our Goal with this Project is to scrape the titles and their respective links, of a QUERY the user searched for.
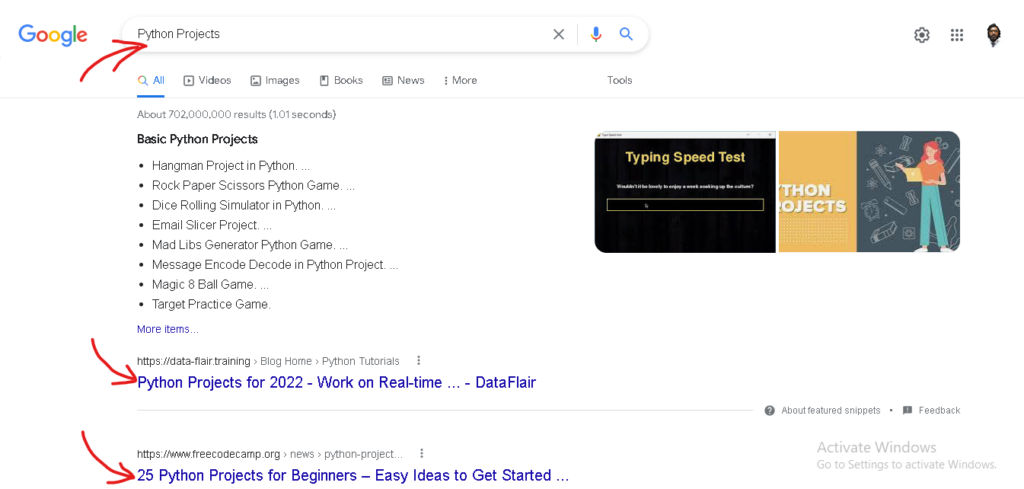
2. Find the div using HTML Agility Pack
3. Use HTML Agility Pack in C# to Scrape Google SERPs (Extract and save titles and links)
Advantages to Scrape Google SERPs?
This can be a small step for a Bigger Project. For example, You can expand it and prepare a full Data Study and find out What Ranks better on Google. And what Meta Descriptions, Titles, And Tags, that Ranking Content uses.
Like I’m personally working on, it and will definitely share it with you guys, once I complete it.
Be sure to Subscribe to our email list, and YouTube Channel, if you don’t want to miss it.
Now let’s do some C# Web Scraping with HTML Agility Pack.
Before moving on to the Actual Project, let’s understand in simple terms…
What is SERP scraping?
SERP stands for Search Engine Results Page) It is the process of scraping (saving) google search results using Web automation. In our case, we are doing Python Web Scraping with Beautiful Soup and Selenium. The details are discussed in the Blog Post.
How do you crawl in Google SERPs?
It depends on the Project. In our case, we are only looking for Titles and their associated links. And hence are only crawling for Titles and their Links in the Google SERPs (Search results). But more can be done, as you can also crawl meta descriptions, tags, etc.
Now, as you have gotten a basic understanding of what we'll be using.
Let's Scrape Google SERPs by C# Web Scraping with HTML Agility Pack.
Confused?
Don't worry! We'll answer all your Questions in Detail.
Here’s what we’ll be covering in detail Step-by-Step:
1. HTML Agility Pack
2. C# Web Scraping with HTML Agility Pack to Scrape Google SERPs
3. C# Web Scraping with HTML Agility Pack to Scrape Google SERPs (Source Code)
4. C# Web Scraping with HTML Agility Pack to Scrape Google SERPs (Output)
Before we move on to the Project, you need to complete this Step.????
Downloading & Setting up (C# + Visual Studio)
Ignore it, if you already have it installed!
Now, Let's move on to the Project.
HTML Agility Pack
Here are some FAQs that will clear the concept regarding HTML Agility Pack.
What is HTML agility pack C#?
HTML Agility Pack is a package that can be imported into Visual Studio. Used for Web Scraping, with C#. We will be using it for Google SERPs Scraping.
Is HTML agility pack free?
Yes! HTML Agility Pack is free to use for coding enthusiasts like you. You can easily add it from your Nuget Packages in Visual Studio while using C#. The details are mentioned in this Blog Post.
What does HTML agility pack do?
HTML Agility Pack makes it easier to do any Web Scraping task when using C# and Visual Studio. In our Project, we will use it for SERPs Scraping. And will Scrape the Titles and links of Google Search Results.
How do I add HTML agility pack to Visual Studio?
To add HTML Agility Pack go and Right Click on Dependencies (under Solution Explorer), then select Nuget Packages, from the dropdown menu. A window will open There Search for HTML Agility Pack, and install the one with the most ratings. I've shared the details in this Blog Post.
C# Web Scraping with HTML Agility Pack to Scrape Google SERPs
I also Published a short Video, I highly recommend you check it out, to fully grasp the concept.
If you go ahead and open your web browser and go and search for something online like
“what is web scraping”
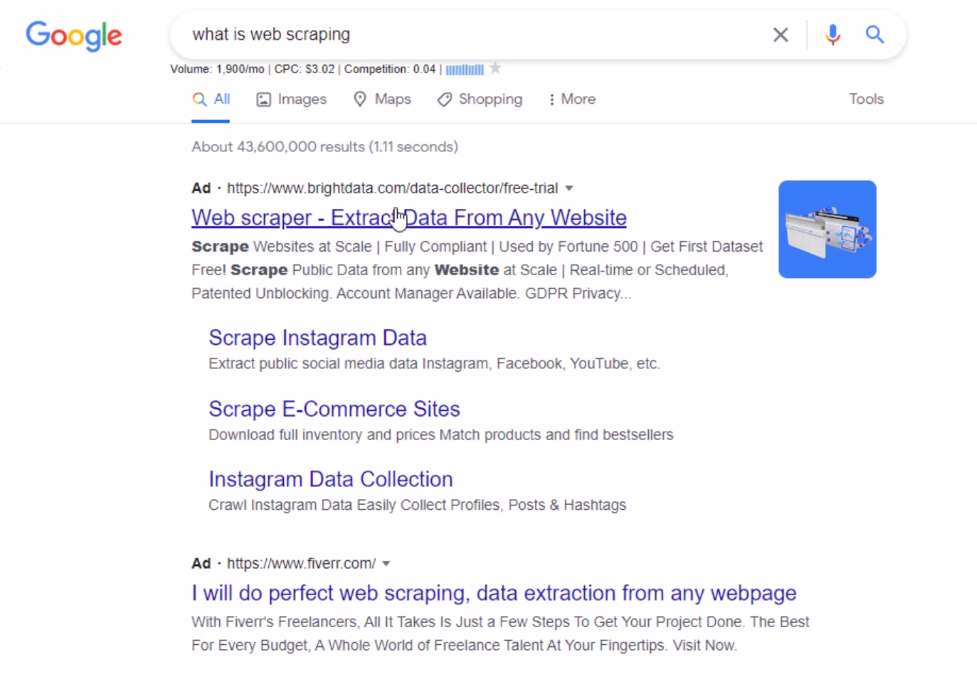
As You can see google will show you these search results up to multiple pages.
What we want to do with web scraping is to scrape this page with our code and read these links and titles.
So, let's open visual studio and create a new project.
Go with a basic console application.
Let's name the Project as Serp Scraper and next, select .NET 5 now and hit create.

So, this is our main function here.
Let's start.
So what I'm going to do now is: To create a function that you can copy and you can use in any application you want.
This is our basic method. We pass the query(what user searches), and number of pages (Till what limit of pages we want the data to be scraped)
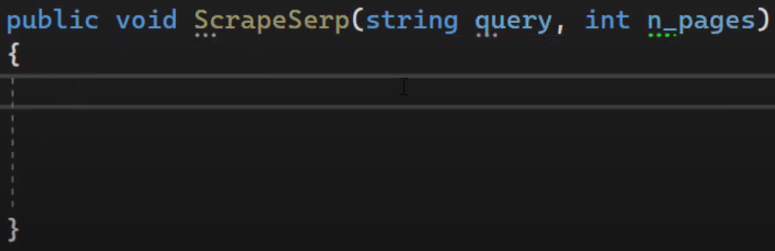
To scrape with C# you want to use a Library called html agility pack.
So go here to dependencies and then manage Nuget packages.
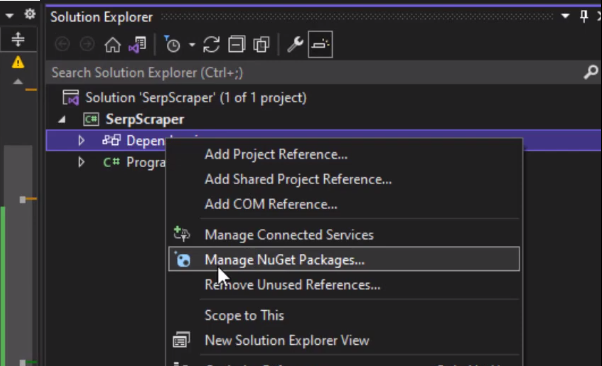
And simply go to browse here and then search for html agility pack, and install it.
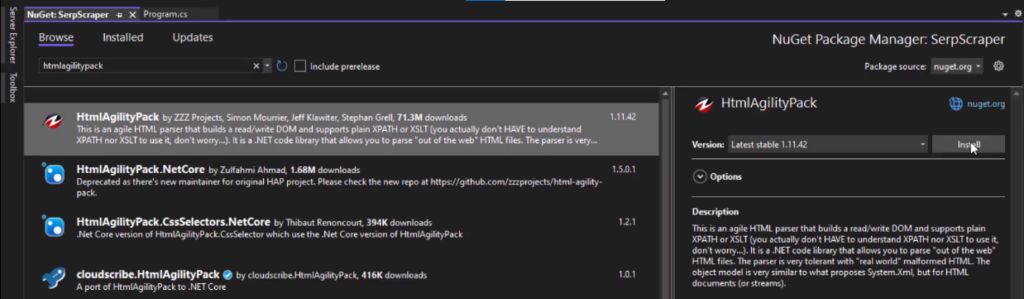
Now we have everything to start scraping google.
Let's go back to google.
So mainly in this scenario today, We are going to scrape the title and the URL.
The idea is the same for everything here. But to make things simple for beginners, we're going to scrape the title and the URL.
So, I will create a class a simple class that holds two properties.
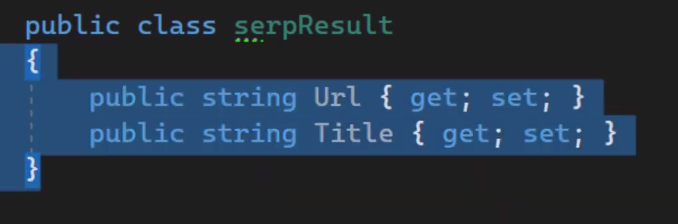
Let's say the first property (string) is the url. The second one is the Title.
So, now after you created this class this method the “scrape serp” will now return a list of “serp results”.
Change the void here to list of “serp result.”
Create a new list.
So now we have an empty list of “serp results” and at the end we will return this list.
In between we are going to scrape and fill this list with google search results.
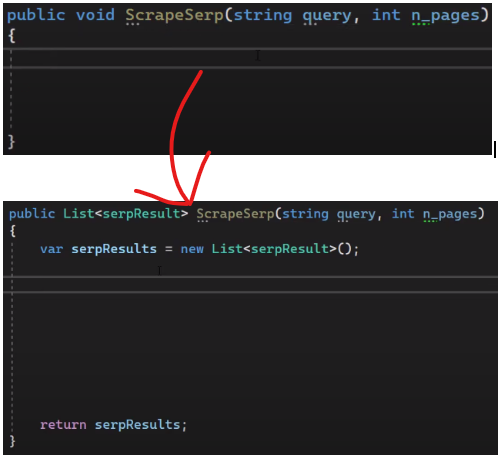
Now we will look from page or page till the end of ( number of pages that you define).
We'll do that by creating a loop starting from the first page and going until we reach less than or equal to a number of pages.
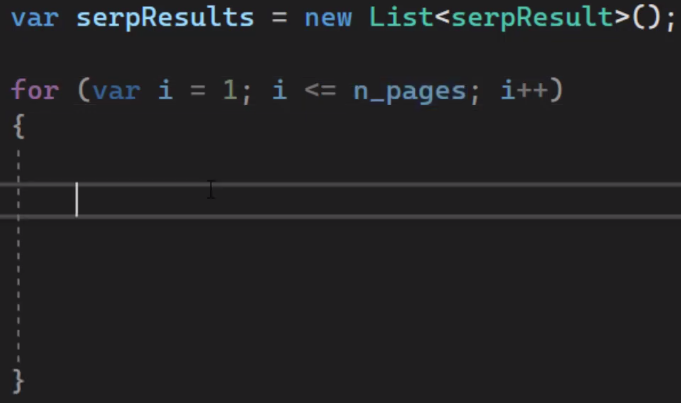
Let's say number of pages is a three it will loop from one to three.
Now in the loop, we are going to open google search results page and download the html document.
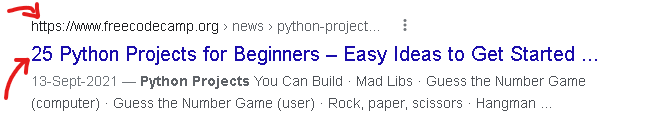
Let's go back here to google. If you right click and go to view page source.
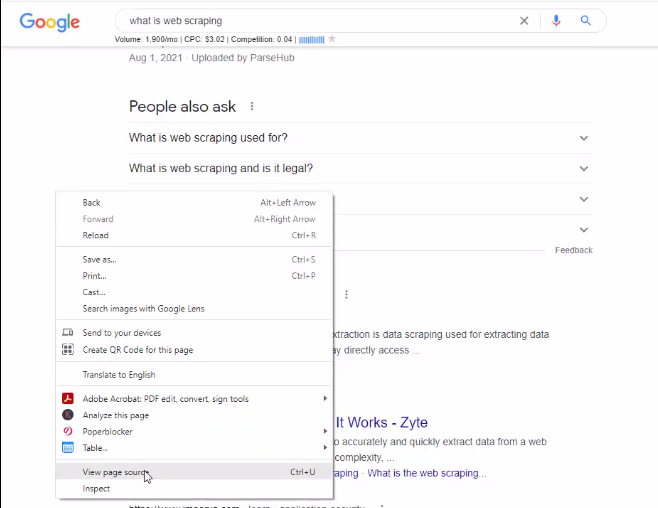
You will see this is the page source (the html code) behind this page.
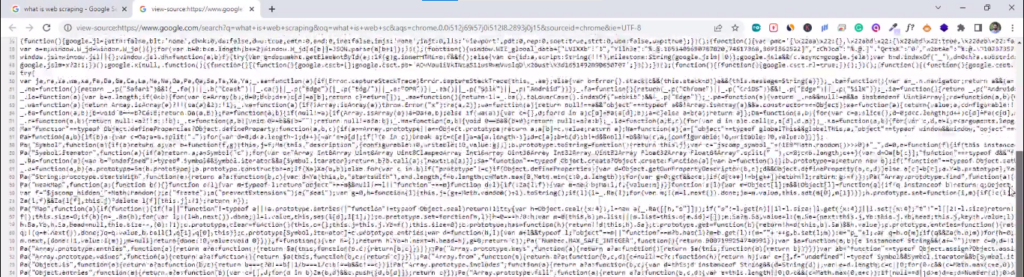
In our case, we want to scrape this html code.
Now we're going to use the power of scraping to start reading this html code.
so the first line is to define the URL that you are going to open and navigate to.
//start
var url = "http://www.google.com/search?q=" + query + " &num=100&start=" + ((i - 1) * 10).ToString();
HtmlWeb web = new HtmlWeb();
//end
Now we have the URL we can open it with html agility pack.
It's time to define what we call a user agent.
//start
web.UserAgent = "user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36";
//end
This agent here will help in avoiding sometimes the re-captcha and avoiding looking as a bot when you open google.
So, it's important to add this user agent parameter here.
Then let's load the URL. Simply define a new html document and load the url inside this web object.
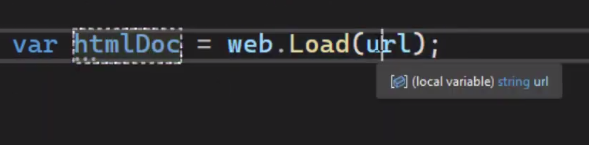
Now we have the html document. We can scrape it, read it and extract the data that we want.
The next step is to create the collection of nodes that's holding the google search results.
Define a new html node collection, called nodes.

Within the Code
We are going to the html document
Then to the document node
And then we are selecting a node with A specific class.
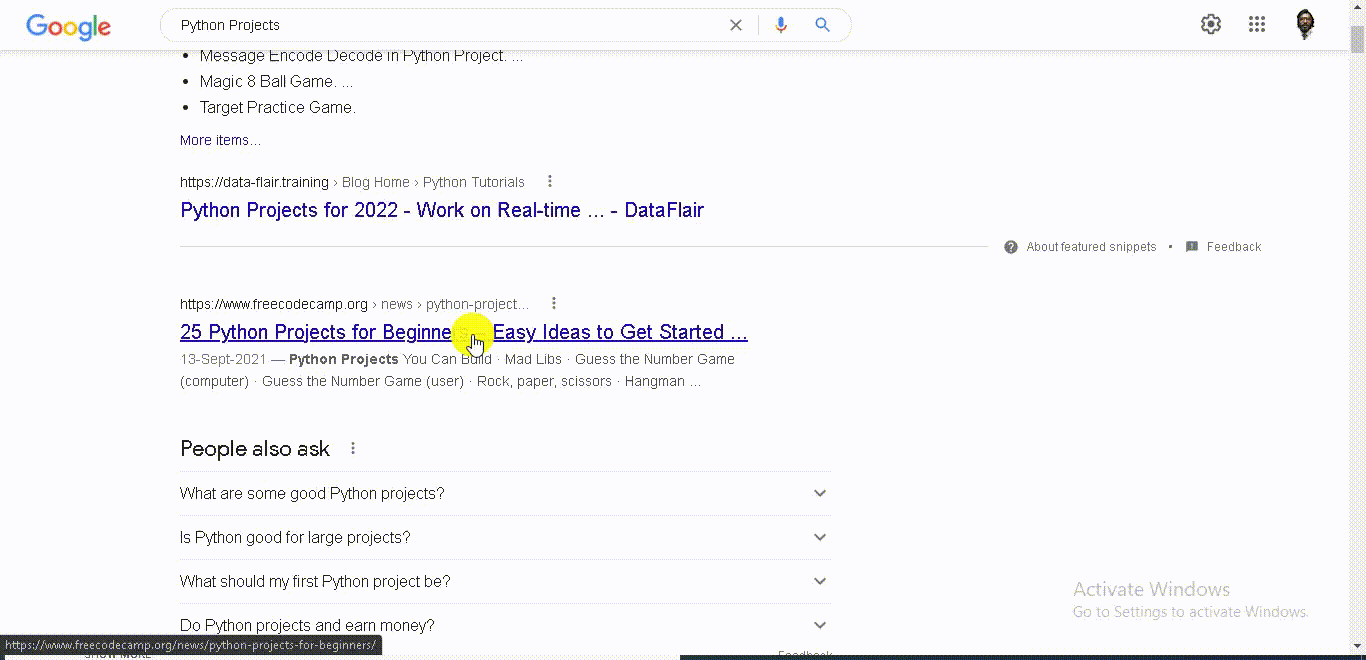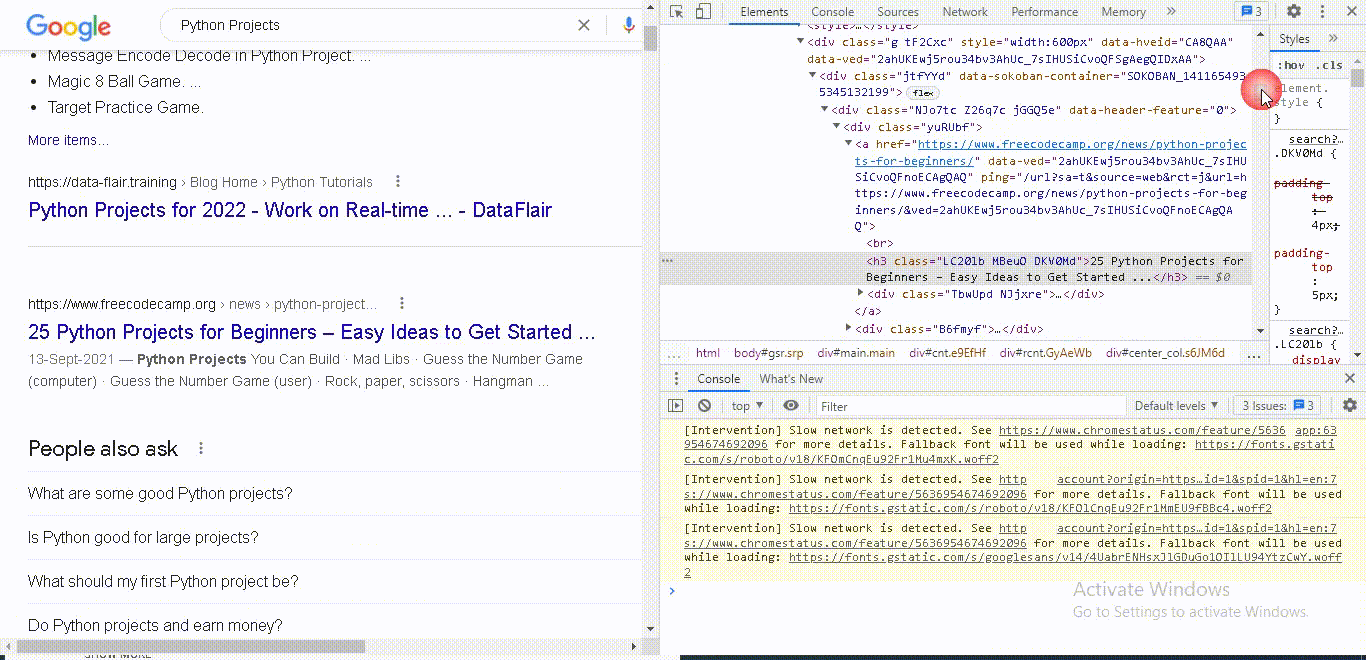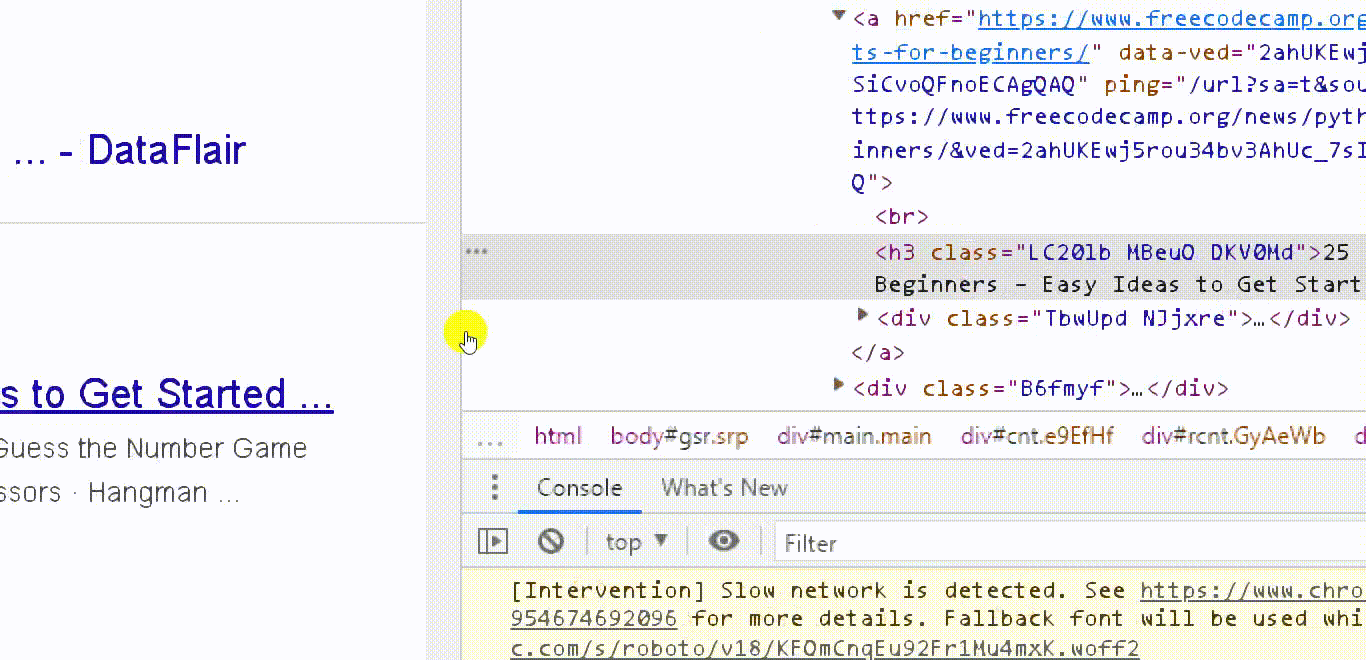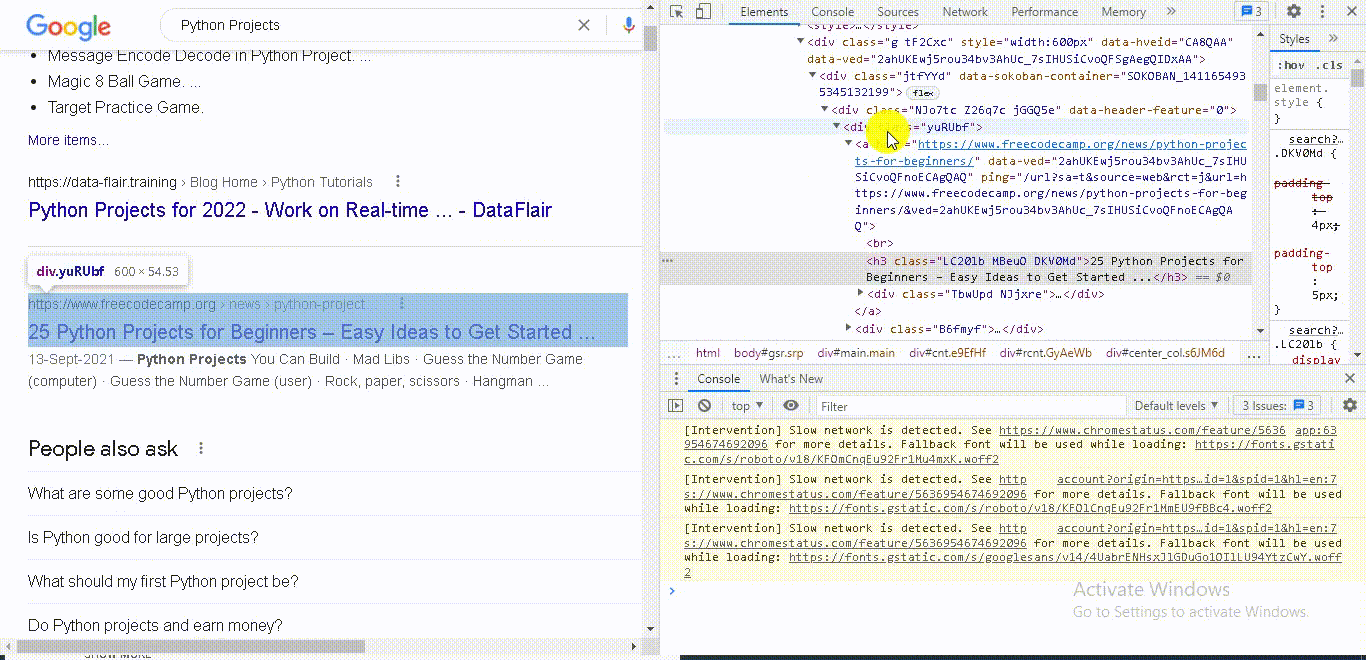
Let's see in the document where we can find it.
If you go back here to search results and right click inspect you will see this is the class you want.
This is the div with the class “y u r u b f.”
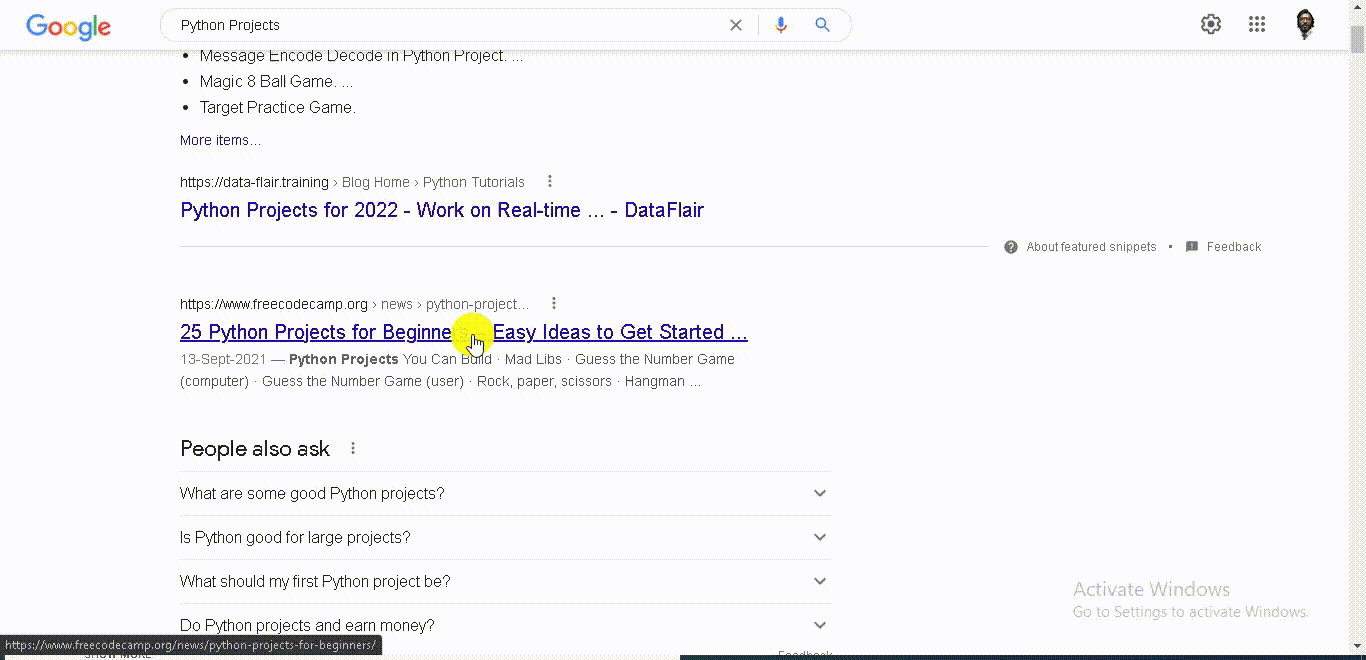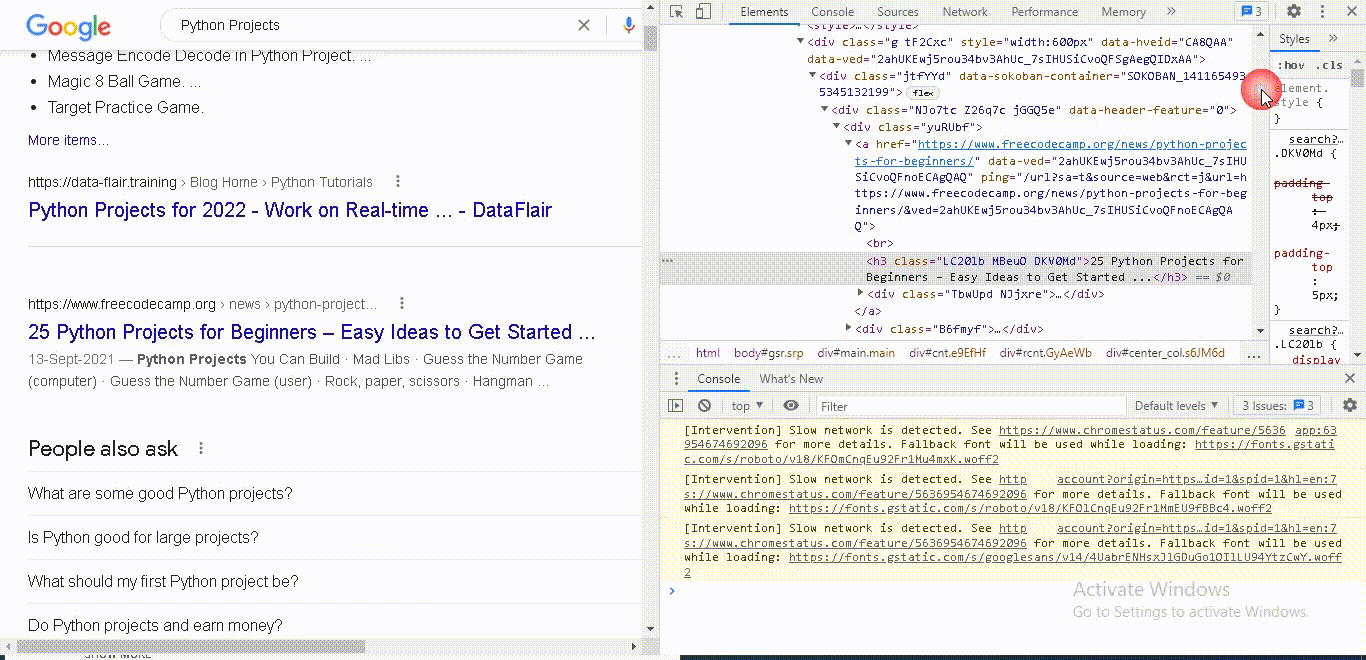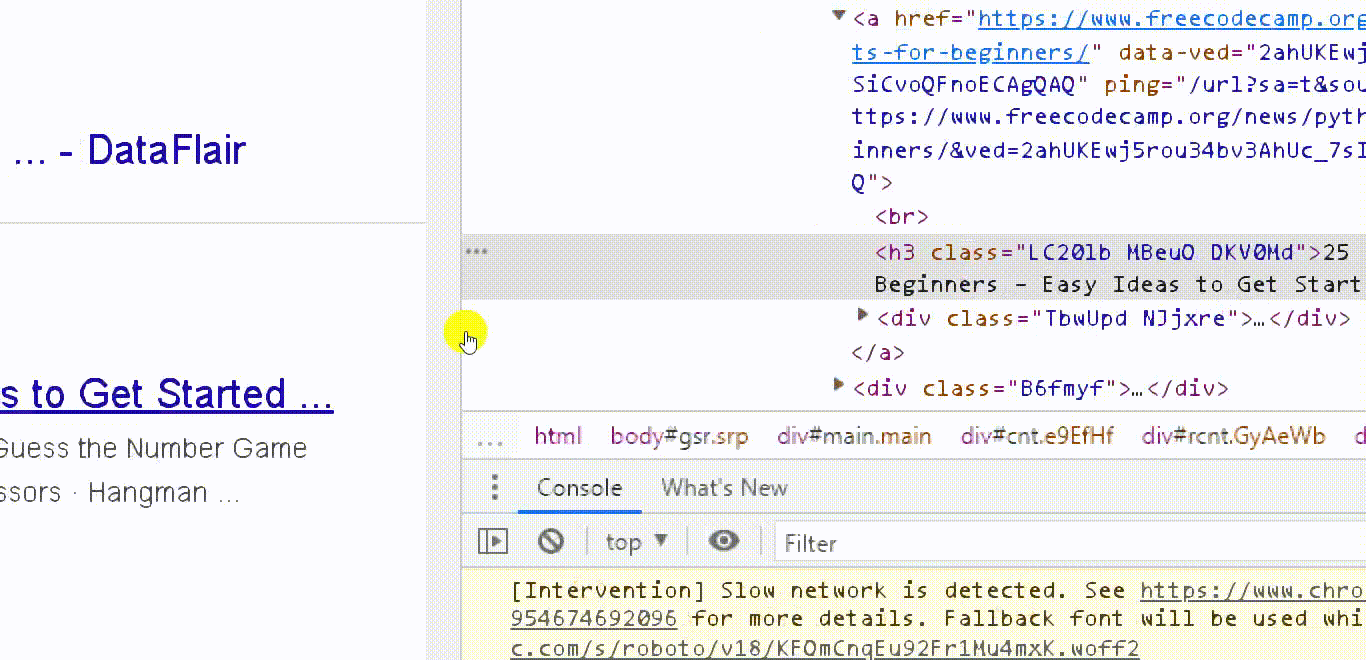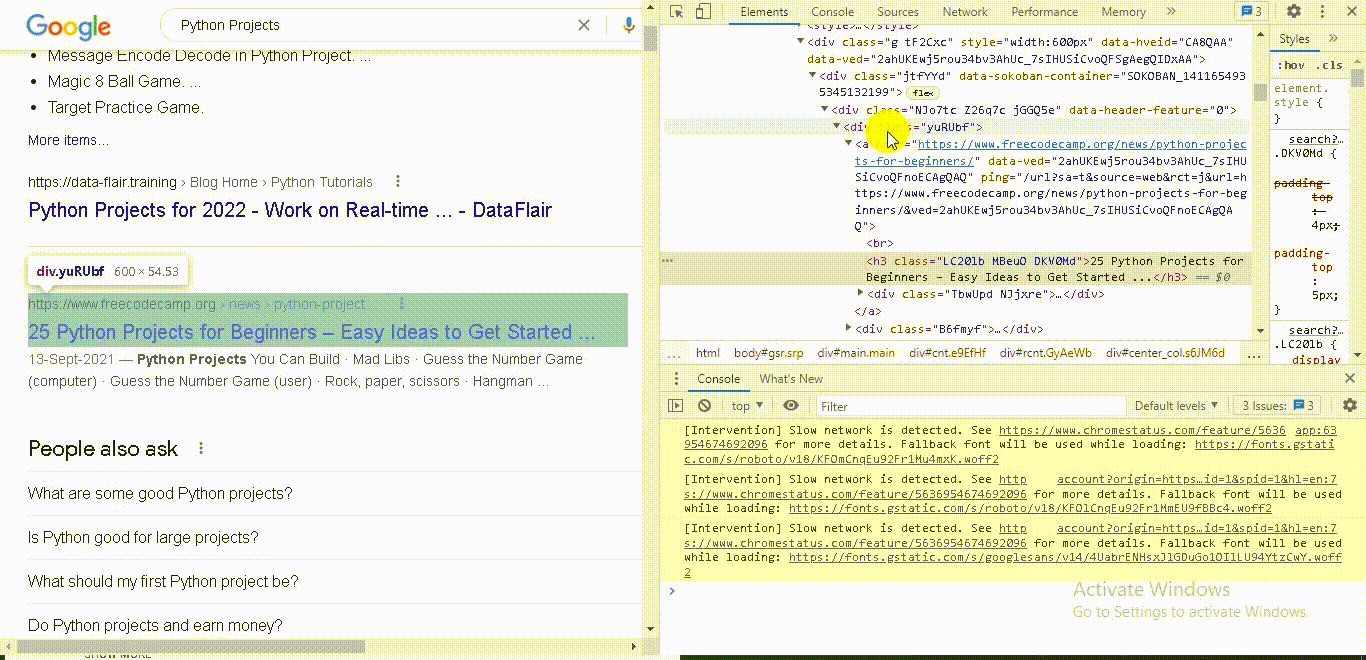
So, we are selecting all the nodes with this class.
Now we have the div with this class we can read the link and the title from this “Div class.”
Now we are going to loop for every tag inside these nodes and read the title and the link.
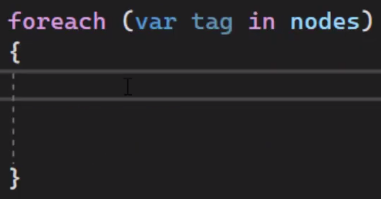
So define and use “serp result” object from this class.

Let's now get the anchor tag which is the link tag
And the “h tag” which is the search result tag or Heading.
Here's how it looks like.
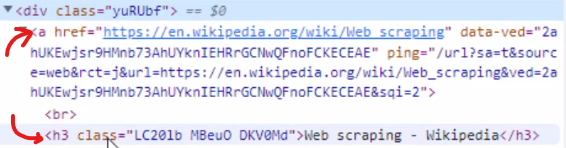

Above we are capturing the “href” property for our anchor tag, and the Heading Text form “h3” tag.
Now we have them both
So, we got the url & the title
Let's add them to the list “serp results.”

Finally, we have the search results added to our list and that's it.????????????
Calling it in the Main Function
We can call it from the main function let's test it.
And I will pass a query.
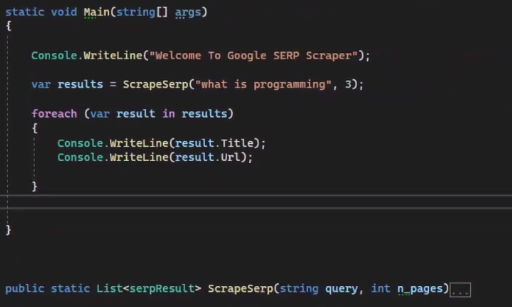
Make sure to make this “ScrapeSerp” method also static, to work properly.
C# Web Scraping with HTML Agility Pack to Scrape Google SERPs (Source Code)
Here's the source code for the Project. You can also check it out on Github.
//start
using System;
using System.Collections.Generic;
using System.Linq;
using HtmlAgilityPack;
namespace SerpScraper
{
internal class Program
{
static void Main(string[] args)
{
Console.WriteLine("Welcome To Google SERP Scraper");
var results = ScrapeSerp("what+is+programming", 3);
foreach (var result in results)
{
Console.WriteLine(result.Title);
Console.WriteLine(result.Url);
}
Console.ReadLine();
}
public static List<serpResult> ScrapeSerp(string query, int n_pages)
{
var serpResults = new List<serpResult>();
for (var i = 1; i <= n_pages; i++)
{
var url = "http://www.google.com/search?q=" + query + " &num=100&start=" + ((i - 1) * 10).ToString();
HtmlWeb web = new HtmlWeb();
web.UserAgent = "user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36";
var htmldoc = web.Load(url);
HtmlNodeCollection Nodes = htmldoc.DocumentNode.SelectNodes("//div[@class='yuRUbf']");
foreach (var tag in Nodes)
{
var result = new serpResult();
result.Url = tag.Descendants("a").FirstOrDefault().Attributes["href"].Value;
result.Title = tag.Descendants("h3").FirstOrDefault().InnerText;
serpResults.Add(result);
}
}
return serpResults;
}
public class serpResult
{
public string Url { get; set; }
public string Title { get; set; }
}
}
}
//end
Make sure to use the code wisely.
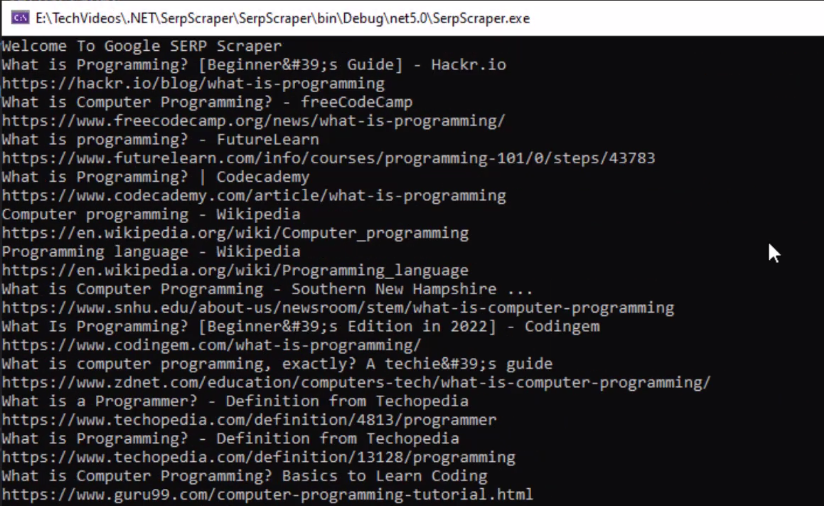
C# Web Scraping with HTML Agility Pack to Scrape Google SERPs (Output)
As you can see we successfully gathered the information we needed.
Conclusion
I hope you successfully completed the Project. Congratulations. You're finally using Programming to solve Real World Problems.
Wish you Luck in your learning.
If you have any Problems regarding this Project or coding in general. You can ask in the comments below.
Also check out this Dope C# Project, on your way out.????
Take care, and Happy Coding!
..